 Like most developers I spend a lot of time keeping my skills up to date as new technologies and demands emerge. Recently I have been learning a bit about non-relational databases, specifically CouchDB, to understand what this approach means and how it might be useful. I still have a lot to learn about this technology, but thought it might be interesting to share and reflect on what I have learnt so far. In this post I will attempt to introduce CouchDB, how you use it and some of the concepts involved. I won't be able to show the full capabilities of CouchDB in one post so a lot will be missed out, including some of its more powerful features such as replication, but hopefully it will be a start.
Like most developers I spend a lot of time keeping my skills up to date as new technologies and demands emerge. Recently I have been learning a bit about non-relational databases, specifically CouchDB, to understand what this approach means and how it might be useful. I still have a lot to learn about this technology, but thought it might be interesting to share and reflect on what I have learnt so far. In this post I will attempt to introduce CouchDB, how you use it and some of the concepts involved. I won't be able to show the full capabilities of CouchDB in one post so a lot will be missed out, including some of its more powerful features such as replication, but hopefully it will be a start.
CouchDB is very different from relational databases like MySQL or Oracle in the way it handles and processes data. Instead of storing data in tables that are connected though joins in queries it stores data in documents, more specifically JSON objects and uses Map and Reduce functions to give us the data we with to see; I'll go into more detail about Map/Reduce later. Another key difference is that CouchDB does not require special drivers or connection through an unusual Internet port number. All operations are conducted through HTTP using REST – a system where we can use HTTP verbs (like GET, POST, PUT etc) to work with the JSON formatted data. This is a real advantage when you come to integrating CouchDB with an application – you don't need special drivers or software or to worry about configuring your web environment in a particular way. If your programming language can handle JSON objects and make HTTP requests then the option of using CouchDB is open to you.
Time for a test drive
So let's dive in and try out CouchDB for real. I'm going to use the example of a dataset that contains product listings and customer reviews of these products. I am sure you will have seen this sort of idea when visiting online retailers. The data here will be simplified, in a real system there will be many more factors to consider, but here I want to keep things simple. If you haven't already then install CouchDB, you will find instructions here: http://wiki.apache.org/couchdb/Installation. There used to be a service that hosted CouchDB instances in the cloud, but this is not currently available. However, I have been told that this will be back soon. As we are humans and not machines let's use a friendly interface to CouchDB called Futon. This is a bit like PHPMyAdmin in that it gives us a web site for our CouchDB installation where we can work with data and manipulate it.
Futon can be found on a local installation of CouchDB by typing: http://localhost:5984/_utils/ in your browser. In the bottom right hand side of the window you might see a message saying “Welcome to Admin Party! Everyone is admin.” - this is important as it means that your database is not secured, anybody that can connect to it can add and remove data. This is fine on a local machine but not what you want on any server! In fact I am a bit surprised that this is the default. You can set up an admin account by clicking “Fix this” and specifying a user name and password. Later, if you wish to secure databases you will need to go into the database, click on “Security” and you can add names and roles in the form of arrays, so it should look something like this: [“user1”, “user2, “user3”] or for one user [“user1”]. To connect from a program you will need to use HTTP Basic authentication with the URL. For more information on security consult the CouchDB documentation.
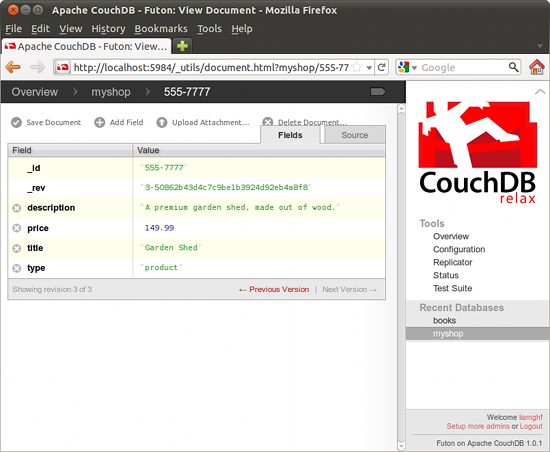
Click on “Create Database” in the top left and specify the name as “myshop”. Once you do this you will be taken into your brand new database, you can also get into it in future by simply clicking the name in Futon. Now click on “Create Document” and you will get a form asking you for an “_id” property. Make this something meaningful like maybe something that could be a catalogue number for your fictional shop. I am going to use “555-7777”. Click the little green tick at the end. Now click “Add Field” click on the “unnamed” text and change it to “title”, again click the little green tick to save. Double click where it says “null” beside it and put in “Garden Shed” (with quotes). Add in another field named “description” and make up some text for this, then put in a “price” field” - “£149.99” should be good. Lastly add a field with the key “type” and the value “product” - we will need this later on.
Now click “Save Document”. Congratulations – you've just created your first CouchDB record! Did you notice that you didn't have to think about the structure of your tables first? That is because CouchDB is schema-less – different records can have different fields and CouchDB will cope. Click back on the database name (in the top left) and then go ahead and create a few more product records for practice, with very different prices. When you have finished, click on the grey signpost icon in the top right, this will show you a raw view of the data, as a JSON object. This is how it will look to another program. Notice the automatically assigned “_rev” field, this indicates the revision of a document, you can see old versions of the document until you compact or clean the database.
A simple view: What products are in our database?
Now we have some data, let's try to query it. The starting point is a CouchDB view, this is less complicated than a Map/Reduce query but is still a very useful way to query the database. In the top right is a drop down box with the title “View”, select “Temporary view” to start. Now you will see a screen with boxes to enter Map and Reduce queries. In the “Map” box a default query will be populated. This simply iterates though each record and outputs it as is – with a key for each document of “null”. Go ahead and run it. Let's change this function so it outputs a list of documents with a key of the catalogue number (or _id as specified in the database) and only one value: the title of the item. Change the Map function to read:
function(doc) {
emit(doc._id, doc.title);
}
When you run this you will get the desired results. If you save your query it will run much more efficiently and will be suitable for use in production systems. Press “Save As” and enter “_design/myshop” for the “Design Document” field and “product_list” for the view name. Once saved you will see that grey signpost again, click it to see how your view looks in raw form. What if you just want to see one result? You can filter this view easily by key, so if we want to see only the result for catalogue number “555-777” we would add ?key=”555-777” to the end of the URL. If you want to see a range try adding ?startkey="555-7777"&endkey="555-7778" to the end of the URL.
So what if I only have £100 to spend, what can I buy? This query will tell me:
function(doc) {
if (doc.price < 100.00)
emit(doc._id, doc.title);
}
A Map/Reduce Query – Prices by band
Map/Reduce is quite a large subject, and I am only just starting to understand it. So here I will just do a very basic version to get the idea across. CouchDB is written to be native to distributed computing, so the idea of Map/Reduce is designed to work across multiple servers. So in order to do something like an aggregate query in SQL we break it down into two steps – Map and Reduce. Map operates a bit like a tally, and Reduce counts up the number in the tally. The advantage of doing things this way is that you can run Map queries on multiple servers and have one Reduce query that adds them all up. Well that is as far as I have got with it at the moment, so more is probably possible and that description might not do it justice!
A simple use in our database might be to work out how many items are in price bands, this is a fairly common thing to see on Internet shopping sites. Create a new temporary view and enter this for the Map function:
function(doc) {
if (doc.price > 300)
emit("Above £300", 1);
else if (doc.price > 99.99)
emit("£100 - £300", 1);
else
emit("Below £100", 1);
}
You can see all the above function does is test the price of each item and emit a “1” if it is in a band. Try running it and you will probably see the a couple of the price band descriptions repeated. If you don't try adjusting the queries to be work with the data you entered. Save the query and then enter this as the Reduce function:
function(keys, values, rereduce) {
return sum(values);
}
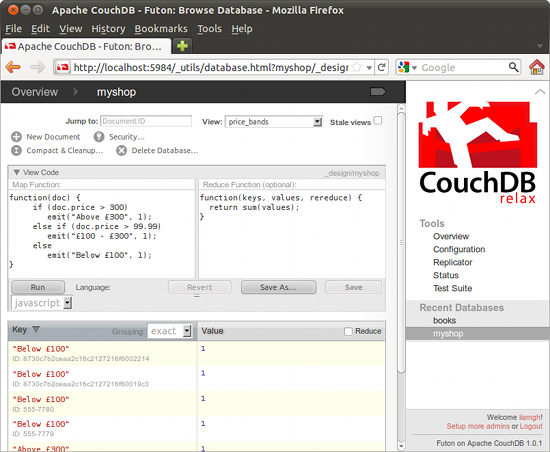
If you tick the “Reduce” checkbox on the right of the results section and rerun you should see a price band summary. Each key and value pair produced by the Map function is passed into the Reduce function and then processed. Sometimes CouchDB will decide it is more efficient though to break up the processing task, so what it will do is run the Reduce function for a few results at a time. It will then take the results generated by each run of the Reduce function and run these through the Reduce function again, but with the rereduce argument set to true. When this happens the keys argument will be null and the values argument will be an array of the results of the previous runs of the Reduce function. This is important to note as you will have to code your Reduce functions in some circumstances to take account of this. This may seem complicated, but think of it as being like eating a big pie, you need to cut it into pieces to eat it – CouchDB is doing something similar – organising the processing into manageable bits.
Joining documents – attaching customer reviews to products
No internet shopping site would be complete without customer reviews. I get nervous about buying anything unless I can see customer reviews, so let's add them to our database. Here things get interesting, we could add these into the documents for our products, however this might not be a great solution. It would mean that the record would be locked for update while a review is being added. This would cause us problems as the usage of the database grows heavier. So let's keep the customer reviews in separate documents and join them on to the product record.
Go back to the database and add a few reviews. The first one should look something like this:
title: “Don't buy this shed”
type: “review”
cat_id: “555-777”
body: “This shed was terrible, it fell down as soon as I bought it.”
You can leave the _id field as it is if you want, a unique value will be assigned. Enter a few review records, with more that one for some products. In a web page about a product we would want to see the product details and the reviews together, so we need to join the documents somehow so we can get all of the information needed back in one HTTP request.
Under “View” select “Temporary View” again and now we can enter a function in the Map field to join the records up. To achieve this we are going to use a complex key – this is a CouchDB concept of combining an identifier that is common to both records (a bit like a foreign key in a relation database I think) and a second element to the key to decide the ordering of the different types of record returned. Enter this as your Map function:
function(doc) {
if (doc.type=="product")
emit([doc._id,0], doc);
if (doc.type=="review")
emit([doc.cat_id,1], doc);
}
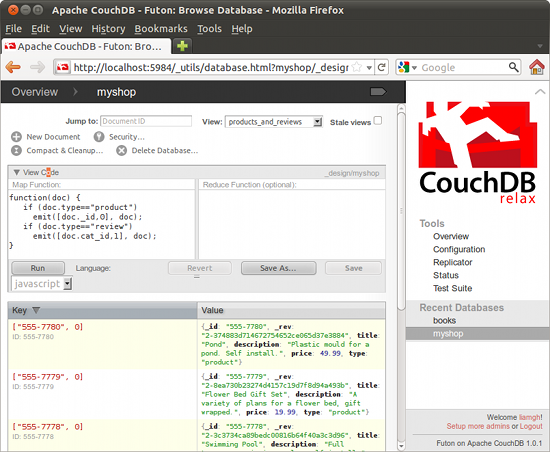
When you run it you should see that product records are returned, and if they have reviews they will follow straight after. There is only one problem now, this view shows us the results for every product, but for our web page we might only want to show one product and its reviews. To achieve this we again use startkey and endkey in a URL. Save the view, run it and then click the little grey signpost again. You should now see the results in a raw form. Try adding this to the end of the URL:
?startkey=["555-7777"]&endkey=["555-7777",2]
By specifying the start and end keys, with a range for the second element that will include the 0 and 1 values output by our query the results should now only show the results for one product, perfect for inclusion in our web page.
Horses for courses
This was a quick summary of what I have learnt so far about CouchDB. It has been good for me as a developer to learn about this approach to storing and processing data. It seems so far that the non-relational approach isn't necessarily “better” than traditional relational databases, but that they are different tools that will perform well in different circumstances. It shows a lot of potential, the use of JavaScript as a query language could prove to be much more flexible that something like SQL stored procedures and the flexibility offered by the schema-less way data is stored could be useful for organisations going through great change and needing their systems to be flexible. It does seem that a bit of standardisation of the data is needed though (e.g. such as adding a “type” field in the example above) in order to get the most out of the query engine. There is a lot I have not been able to cover here, so if this topic interests you dive in and find out more. Let me know in the comments what you discover.
References:
- CouchDB home page: http://couchdb.apache.org/
- Interactive CouchDB tutorial: http://labs.mudynamics.com/wp-content/uploads/2009/04/icouch.html
- CouchDB “Joins” - about:cmlenz: http://www.cmlenz.net/archives/2007/10/couchdb-joins
- Beginning CouchDB, Joe Lennon, Apress, ISBN 978-1-4302-7237-3
- Photo: Das rote Sofa by Dierk Shaefer http://www.flickr.com/photos/dierkschaefer/2739706920/
Re: Starting to relax with CouchDB
Nice post liam. I've been wondering about all these new databases. CouchDB sounds really interesting from your summary. I've just started using Git and it's really improved my programming workflow. I can see how CouchDB could do the same for my relationship with databases.
I am not relaxed about CouchDb!
It seems to me that I have to re-key the field names, when adding subsequent records. That doesn't seem useful.
I would actually want to upload a ODT office document, and take records from the document. CouchDb didn't seem to want to process the ODT file - it just stored a copy of the document. When I manually extracted the XML from the ODT file, CouchDb displayed it, quite nicely. I didn't go further, to try to utilse the XML data, for a fundamental reason. I need to work from the original document and find that manually extracting XML, is an unnecessary process.
BaseX can handle ODT, no problem. I understand that MongoDb can, too, but I am finding that troublesome to install on OS X.
Is it fair to say that, if you were starting out today, you would install MongoDb, and not CouchDb?