 In a recent poll on this site I asked "Do you have, or are you planning to learn, any skills related to Linked Data?". Interestingly 60% of respondents (there were 101 votes) said yes, so I thought I should finally get round to writing up a demonstration app that uses Linked Data to provide the information and jQuery Mobile to provide the looks (and more) for a mobile podcast by subject explorer. The site is written using PHP and was developed quite quickly. Again I will be using the Open University's Linked Data store, but the site could easily be adapted to use other stores, maybe even more than one store. Thanks to the use of jQuery Mobile it would even be possible to take the site and embed it in a thin app on the phone to make it look a bit like a native app. Of course the site is a bit rough and ready and I am sure there are thousands of ways to improve it, so experiment and let me know how you get on in the comments.
In a recent poll on this site I asked "Do you have, or are you planning to learn, any skills related to Linked Data?". Interestingly 60% of respondents (there were 101 votes) said yes, so I thought I should finally get round to writing up a demonstration app that uses Linked Data to provide the information and jQuery Mobile to provide the looks (and more) for a mobile podcast by subject explorer. The site is written using PHP and was developed quite quickly. Again I will be using the Open University's Linked Data store, but the site could easily be adapted to use other stores, maybe even more than one store. Thanks to the use of jQuery Mobile it would even be possible to take the site and embed it in a thin app on the phone to make it look a bit like a native app. Of course the site is a bit rough and ready and I am sure there are thousands of ways to improve it, so experiment and let me know how you get on in the comments.
The site enables uses to find podcasts by subject. It doesn't have as deep as hierarchy as the official OU podcast web site, though this could be added. The first step is to write a bit of common code. In a file named shared.php I wrote functions for making a web request and converting the results into a PHP object, the method was based on my earlier post An approach to consuming Linked Data with PHP. Notice that there is not a lot of error handling, so before use in a production environment you should add code to handle HTTP errors. The contents of the shared.php file are:
// Perform an HTTP request using CURL
function request($url){
// is curl installed?
if (!function_exists('curl_init')){
die('CURL is not installed!');
}
// get curl handle
$ch= curl_init();
// set request url
curl_setopt($ch, CURLOPT_URL, $url);
// return response, don't print/echo
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
curl_close($ch);
return $response;
}
// Send a SPARQL query to the OU endpoint and convert the results into a PHP array
function do_LD_Query($sparql) {
$requestURL = 'http://data.open.ac.uk/query?query='.urlencode($sparql);
$response = request($requestURL);
// container for our data
$data = array();
// initialise SimpleXML object and load it with data
$xml = simplexml_load_string($response);
if ($xml === FALSE) {
return $response;
}
// get the
$results = $xml->results;
// loop through
if (isset($results->result)) {
foreach($results->result as $result) {
$line = array();
foreach ($result->binding as $binding) {
if (isset($binding->uri)) {
$line[(string) $binding["name"]] = (string) $binding->uri;
}
else {
// could pick up xsd data type for right cast
$line[(string) $binding["name"]] = (string) $binding->literal;
}
}
$data[] = $line;
}
}
return $data;
}
?>
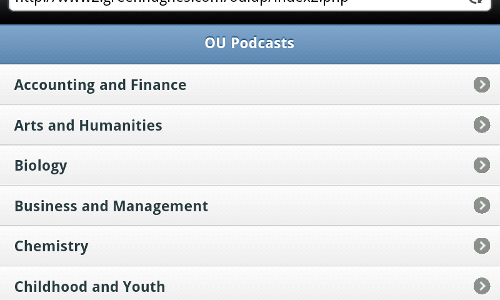
The starting page for the app gives the user the chance to pick the subject that they are interested in. Sadly it takes a few seconds to generate so the screen is blank for a little while. A good addition here would be some sort of "Loading..." notification. As with all pages that generate output for the user on this site it uses jQuery Mobile to render the look and feel. Thanks to this wonderful library our web application can easily look half decent, it also gives the user a good experience. A SPARQL query is used to get the subjects and a jQuery Mobile listview is used to render them on the page. Note for convenience I am getting the jQuery files directly from their server, but for a production site you should host your own copy. This protects you against breakages due to changes and upgrades, it is also more polite as you won't be using their bandwidth! The index.php page looks like this:
/**
* Start page for app
* Displays index of subjects
*/
require_once("shared.php");
ob_start("ob_gzhandler"); // compress output
// generate and SPARQL query to find out subjects
$sparql =
"PREFIX rdfs:
PREFIX skos:
SELECT DISTINCT ?subject ?subject_label {
?p
?subject skos:inScheme
OPTIONAL {?subject rdfs:label ?subject_label} }
ORDER BY ?subject_label";
$results = do_LD_Query($sparql);
// generate a list of unique subjects
$subjects = array();
foreach ($results as $result) {
$title = $result['subject_label'];
if (empty($title) ) {
$title = $result['subject'];
}
$subjects[$result['subject']] = $title;
}
?>
OU Podcasts
-
// generate a link for each subject
- %s
foreach ($subjects as $subject => $title) {
printf("
", urlencode($subject), htmlentities($title));
}
?>
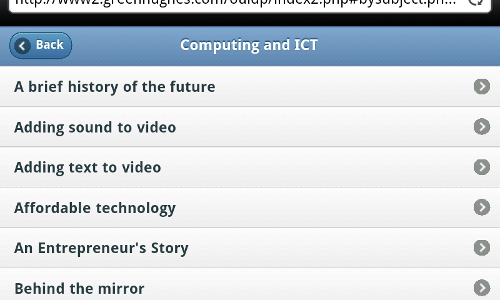
In the index page the subject is used as a key to determine the content of the next page. Once a user selects a subject we need to show them a list of available podcasts. The subject is passed through a query parameter to the page bysubject.php, which is below.
/**
* Podcasts by subject list
*/
require_once("shared.php");
ob_start("ob_gzhandler"); // compress output
$subject = $_GET['subject'];
// Generate the SPARQL query
$sparql = sprintf("
PREFIX rdfs:
PREFIX xsd:
SELECT DISTINCT ?podcast ?title ?download ?subject_label
WHERE {
?podcast
?podcast
?podcast
rdfs:label ?subject_label;
}
ORDER BY ?title", $subject, $subject);
// run it
$results = do_LD_Query($sparql);
?>
- ';
- %s
// build link for each item
foreach ($results as $result) {
$podcast_id = str_replace("http://data.open.ac.uk/podcast/", "", $result['podcast']);
$list_html .= sprintf("
", urlencode($podcast_id), $result['title']);
}
$list_html .= "
";
// if there were no results print an apology
if (sizeof($results)==0) {
echo "
Sorry, there are no podcasts available for this subject.
";
}
else {
echo $list_html;
}
?>
You might noticed the call to ob_start("ob_gzhandler") in the files. This tells the webserver (if it and the client support it) to compress the output of the web page before sending it to the client, which will hopefully speed up the transfer of the page to the mobile device and save the user money by keeping the data volume down. We know in this case that http://data.open.ac.uk/podcast/ is going to be the start of every URL for the podcasts so here it is removed before being used as a key to be passed to the next page, this helps to reduce the size of the page slightly. Now the user has selected a podcast we can show them some more details and invite them to play it on their device. The code for the play.php page is below.
/**
* Play a podcast
*/
require_once("shared.php");
ob_start("ob_gzhandler"); // compress output
$podcast_id = $_GET['podcast_id'];
// some podcasts do not have relates to course and transcripts
$podcast_filter = sprintf("
$sparql = sprintf("SELECT ?title ?depiction ?duration ?comment ?transcript ?format ?download ?course_code ?course_name ?course_url
WHERE {
?podcast
?podcast
?podcast
?podcast
?podcast
?podcast
OPTIONAL {
?podcast
?podcast
?course
?course
?course
}
FILTER (?podcast = %s)
} ", $podcast_filter);
$results = do_LD_Query($sparql);
$title = htmlentities($results['0']['title']);
$depiction = htmlentities($results['0']['depiction']);
$duration = htmlentities($results['0']['duration']);
$comment = htmlentities($results['0']['comment']);
$transcript = htmlentities($results['0']['transcript']);
$format = htmlentities($results['0']['format']);
$download = $results['0']['download'];
$course_code = htmlentities($results['0']['course_code']);
$course_name = htmlentities($results['0']['course_name']);
$course_url = $results['0']['course_url'];
$play_link = sprintf("playfile.php?format=%s&file=%s", $format, urlencode($download));
?>
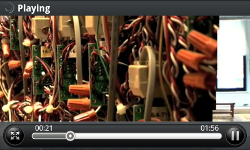
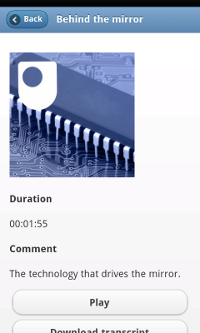 Things get slightly more complicated at this point. As well as a play button, the user also gets buttons to download a transcript of the podcast and view the web page for the course that the podcast relates to. However, not every podcast has information for a transcript or course link, so in the SPARQL query these attributes are surrounded by an OPTIONAL keyword to make sure we get as many details as we can. The buttons for these options are also only generated if this information is available. The FILTER keyword is used here to restrict the results to the podcast that the user selected (thanks to Mathieu d’Aquin for his help with this bit!). Using this approach we can make additional information available to the user which can enhance the value of using the site. This would be a good place to add things like related podcasts, OpenLearn units and courses to make it really easy for the user to explore what is on offer.
Things get slightly more complicated at this point. As well as a play button, the user also gets buttons to download a transcript of the podcast and view the web page for the course that the podcast relates to. However, not every podcast has information for a transcript or course link, so in the SPARQL query these attributes are surrounded by an OPTIONAL keyword to make sure we get as many details as we can. The buttons for these options are also only generated if this information is available. The FILTER keyword is used here to restrict the results to the podcast that the user selected (thanks to Mathieu d’Aquin for his help with this bit!). Using this approach we can make additional information available to the user which can enhance the value of using the site. This would be a good place to add things like related podcasts, OpenLearn units and courses to make it really easy for the user to explore what is on offer.
Once the user taps the Play button ideally we want to be able to pass the media file to the mobile device and it can then play it. This works really well for audio, but of course for video nothing is ever this simple! It turns out that Android devices do not like the MIME type that is sent by the OU Podcast server and will refuse to play video files. However all is not lost, and there is a way round it by changing the MIME type and passing the file through our PHP script. This might use quite a bit of your bandwidth though, so it is an approach to be used sparingly and carefully. The playfile.php file is below.
// Determine if browser is on an Android machine
function is_android() {
// note ! = = not != to test equality based on type
// "Linux Ventana" is an Asus EEE Pad Transformer browser in desktop nomode
return stristr( $_SERVER['HTTP_USER_AGENT'], "Android") !== FALSE
|| stristr( $_SERVER['HTTP_USER_AGENT'], "Linux Ventana") !== FALSE;
}
// main
$format = $_GET['format'];
$file = $_GET['file'];
// check file is from OU pocasts
if (!strpos("http://podcast.open.ac.uk/", $file) == 0) {
echo "Unsupported.";
}
else {
// change format header so android can play file
if ($format == "video/x-m4v" && is_android()) {
$format = "video/mp4";
header("Content-Type: ".$format);
readfile($file);
}
else {
header("Location: ".$file);
}
}
?>
It is worth testing out a variety of devices with the site as it may be necessary to add similar workarounds for other devices.
This approach could be used as the basis for developing all sorts of mobile web sites that deliver an experience optimised for touch screens. Combining the power of Linked Data and Jquery mobile means the development time to produce a site with a good look and feel is dramatically reduced. Using SPARQL queries gives you fine grained control over the data you get back which is very useful for building mobile web pages. Of course users do not need to know about any of this, all they need to know is that you have brought them the information they want in a decent looking way.
You should not host your own copy because
You should not host your own copy because when a user visits site A and requests googles jquery library and then visits site B that also requests googles jquery library the library is either cached on the phone or at the ISP.
The library names are version specific so you will never have the problem of getting a file with breaking changes.
Re: You should not host your copy because
That's a valid argument, however with libraries like this I think you have to be aware of the amount of somebody else's bandwidth you are using, they might not be happy if your app makes a million requests per day for example! Also hosting it yourself can mean you are not relying on someone else to not change the file, removing one possible cause of errors.